백업과 복원
포털은 두 스크립트를 제공합니다 — scripts/backup.sh와 scripts/restore.sh. PostgreSQL 데이터베이스와 workspace 볼륨이라는 두 상태 산출물을 다루며, 백업 시점의 Alembic head를 기록한 manifest를 함께 둡니다.
호스트 sudo 권한 보유 super_admin. pg_dump, tar, cron에 익숙해야 합니다.
백업 내용
v0.10.0 에는 두 디렉터리 명명 형식이 공존합니다.
- CLI 레거시 —
backups/YYYY-MM-DD-HHMMSS/(scripts/backup.sh와 아래 예시에서 사용). - UI / Celery —
backups/(auto|manual)-YYYYMMDDTHHMMSSZ/(apps/backend/tasks/backup.py와/admin/backup페이지에서 사용 — prefix 가 일일 Celery Beat 잡인지 운영자 클릭인지를 표시). 백업 트리거 섹션이 언급하는auto-보존 정리는 이 prefix 를 키로 동작합니다.
두 형식 모두 동일한 postgres.sql.gz + workspace.tar.gz + manifest.json 트리플로 디코드되며 복원 측에서는 호환 — 복원 스크립트(와 UI 복원 엔드포인트)가 둘 다 받습니다.
backups/2026-05-09-030000/
├── postgres.sql.gz # pg_dump --clean --if-exists | gzip
├── workspace.tar.gz # $WORKSPACE_HOST_PATH의 tar -czf
└── manifest.json # 타임스탬프, alembic head, db 크기, workspace 경로
postgres.sql.gz—--clean --if-exists포함 전체 논리적 덤프. 재적용 시 객체를 drop+recreate한 후 데이터 재삽입.workspace.tar.gz— 워커에/workspace로 마운트된 호스트 디렉터리. 스캔별 소스 클론(<scan_id>/source/), scancode 라이선스 탐지 출력(<scan_id>/scancode/scancode.json), cdxgen SBOM 캐시(<scan_id>/cdxgen/)를 포함.manifest.json—timestamp,alembic_head,db_size,workspace_path. 복원 스크립트가 라이브 상태와alembic_head를 검증.
포털은 .env(비밀값 포함 — 별도 비밀 관리 도구로 보관)와 Traefik의 ACME 상태(Let's Encrypt가 몇 분 내 재발급)는 백업하지 않습니다.
수동 백업 실행
bash scripts/backup.sh
출력:
Backup → backups/2026-05-09-030000
✓ wrote backups/2026-05-09-030000/postgres.sql.gz (12M)
✓ wrote backups/2026-05-09-030000/workspace.tar.gz (840M)
✓ wrote backups/2026-05-09-030000/manifest.json (alembic head = 9f1c8d2a3b4e)
Backup complete
backups/2026-05-09-030000
스크립트는 종료 시점에 BACKUP_RETENTION_DAYS(기본 7)보다 오래된 백업을 정리합니다. --no-prune으로 정리 생략 가능.
Admin UI 로 수동 백업
브라우저를 선호하는 운영자라면 /admin/backup이 셸로 떨어지지 않고도 같은 백업·복원 흐름을 노출합니다.
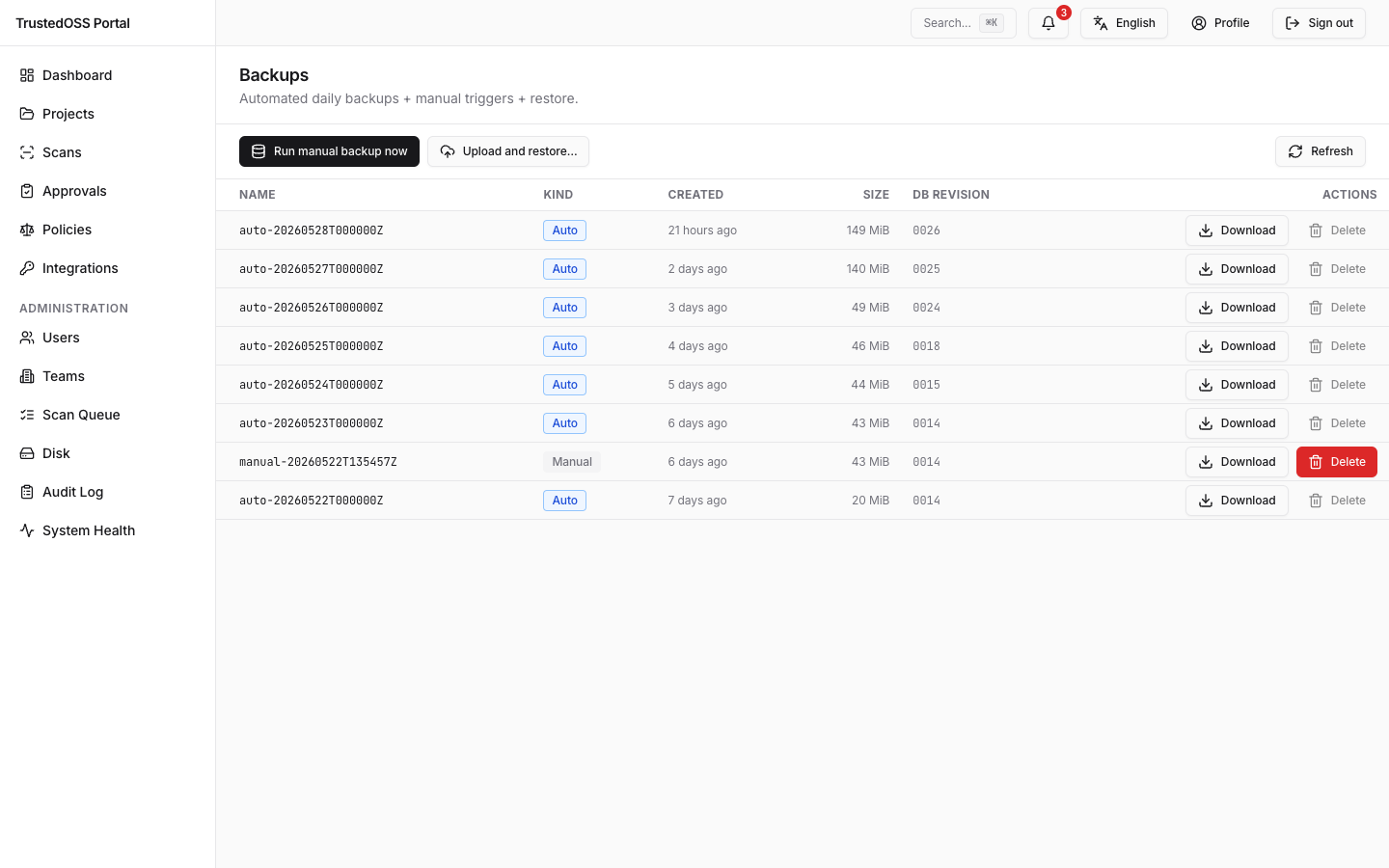
목록 표는 여섯 컬럼을 보여줍니다 — NAME, KIND, CREATED, SIZE, DB REVISION, ACTIONS. 갓 설치된 환경에서는 본문이 인라인 empty 카드("No backups yet…")로 시작합니다 — 툴바의 Run manual backup now 또는 Upload and restore… 로 채우거나 야간 자동 잡을 기다립니다.
백업 트리거
/admin/backup을 엽니다(Admin 사이드바 → Backup).- Run manual backup now를 클릭합니다. 버튼은
super_admin전용입니다. - 포털이 Celery 태스크를 큐에 넣습니다 — 행이 즉시 표에 나타나며 상태
running과 실시간 진행 바가 표시됩니다. - 태스크 완료 시 행이
succeeded로 전환되고 타임스탬프 옆에 Download 링크가 표시됩니다.
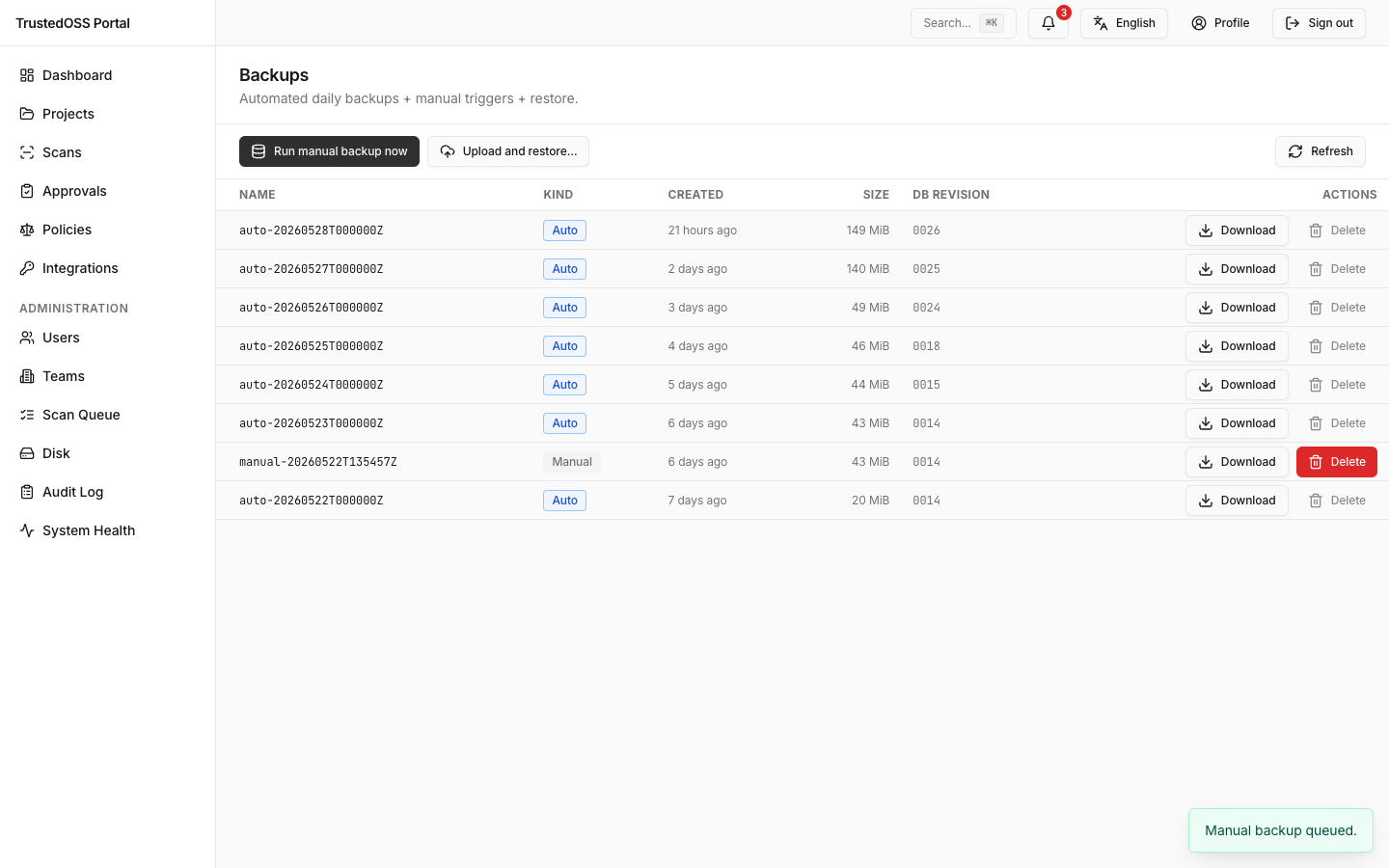
목록 표는 타임스탬프, 크기, auto 배지(Celery Beat가 만든 백업에 부여), Download, Delete를 보여줍니다. auto-tagged 백업은 자물쇠 아이콘으로 표시되며 — 7일 자동 보존 정책의 대상이고 시간순으로 정리됩니다. 수동 백업은 자동 보존 대상이 아니며 Delete를 클릭해야만 삭제됩니다.
Celery Beat 로 스케줄
매일 00:00 UTC의 백업이 apps/backend/tasks/backup.py에 기본 스케줄되어 있으며 추가 구성이 필요 없습니다. v0.10.0 에서 스케줄은 항상 켜져 있습니다 — 비활성화 env 토글이 없습니다(BACKUP_DAILY_ENABLED 스위치는 로드맵 항목). Celery Beat 대신 호스트 측 스케줄러를 선호한다면 자동 백업을 안전망으로 두고 아래 cron / systemd 레시피를 추가하세요 — 두 워크플로는 독립적입니다.
UI 에서 Upload + Restore
Upload + Restore 섹션은 이전에 다운로드한 .tar.gz 아카이브(scripts/backup.sh가 만든 번들)를 받습니다.
- Choose file을 클릭해 아카이브를 선택(최대 10 GB — 더 큰 백업은 CLI 복원 경로를 사용).
- 경고 패널을 주의 깊게 읽으세요. 복원은 라이브 데이터베이스와 workspace를 덮어씁니다.
- 확인 필드에
restore(소문자, 정확히 일치)를 입력하세요. 타이핑 게이트가 매칭될 때까지 Restore 버튼은 비활성화 상태입니다. - Restore를 클릭합니다.
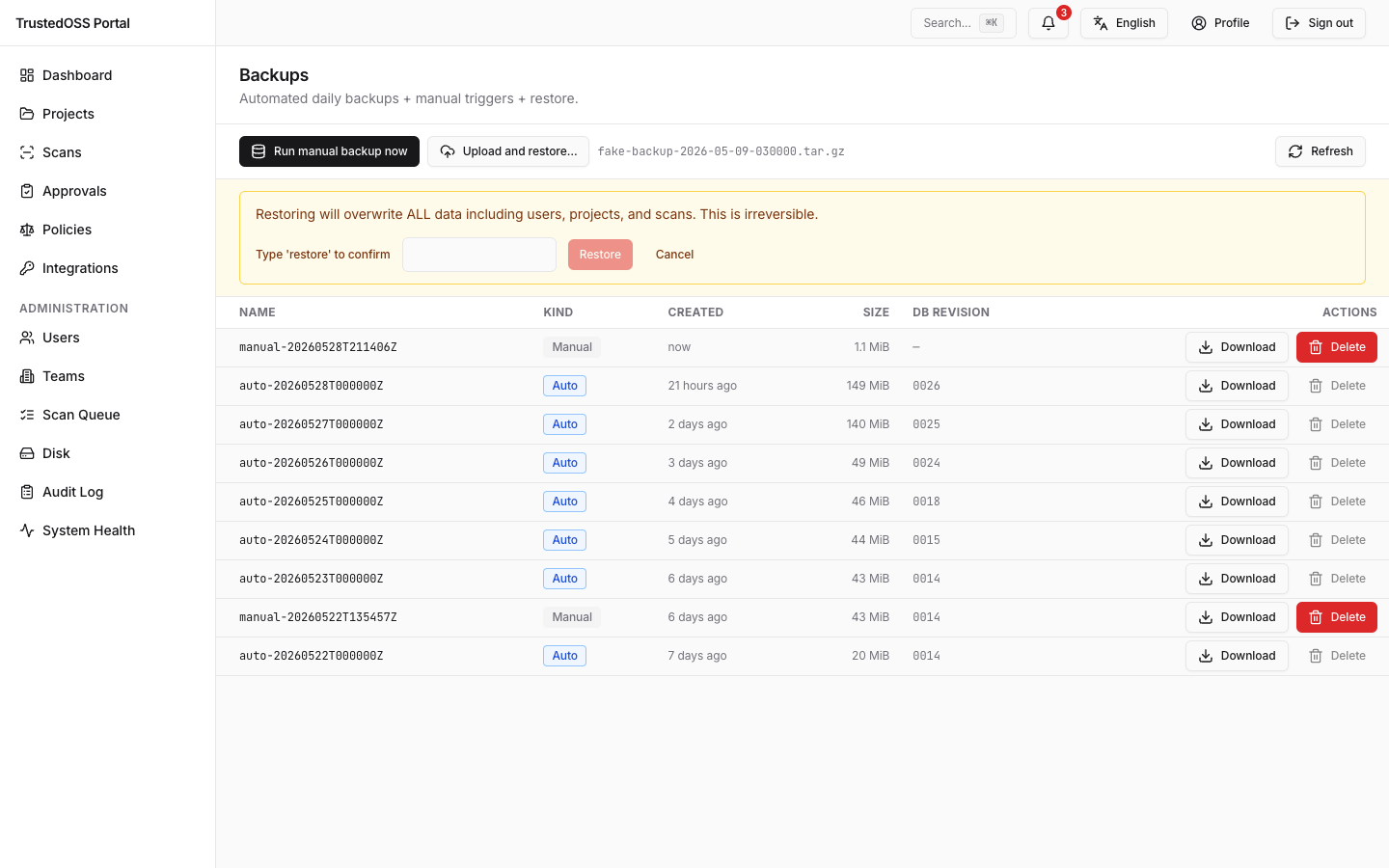
�타이핑 게이트가 일치하면 파괴적 Restore 버튼이 활성화됩니다. 아래 스크린샷은 게이트가 풀리는 순간을 포착했습니다 — 입력된 restore 토큰, 표시된 경고 패널, 그리고 이제 클릭 가능해진 버튼:
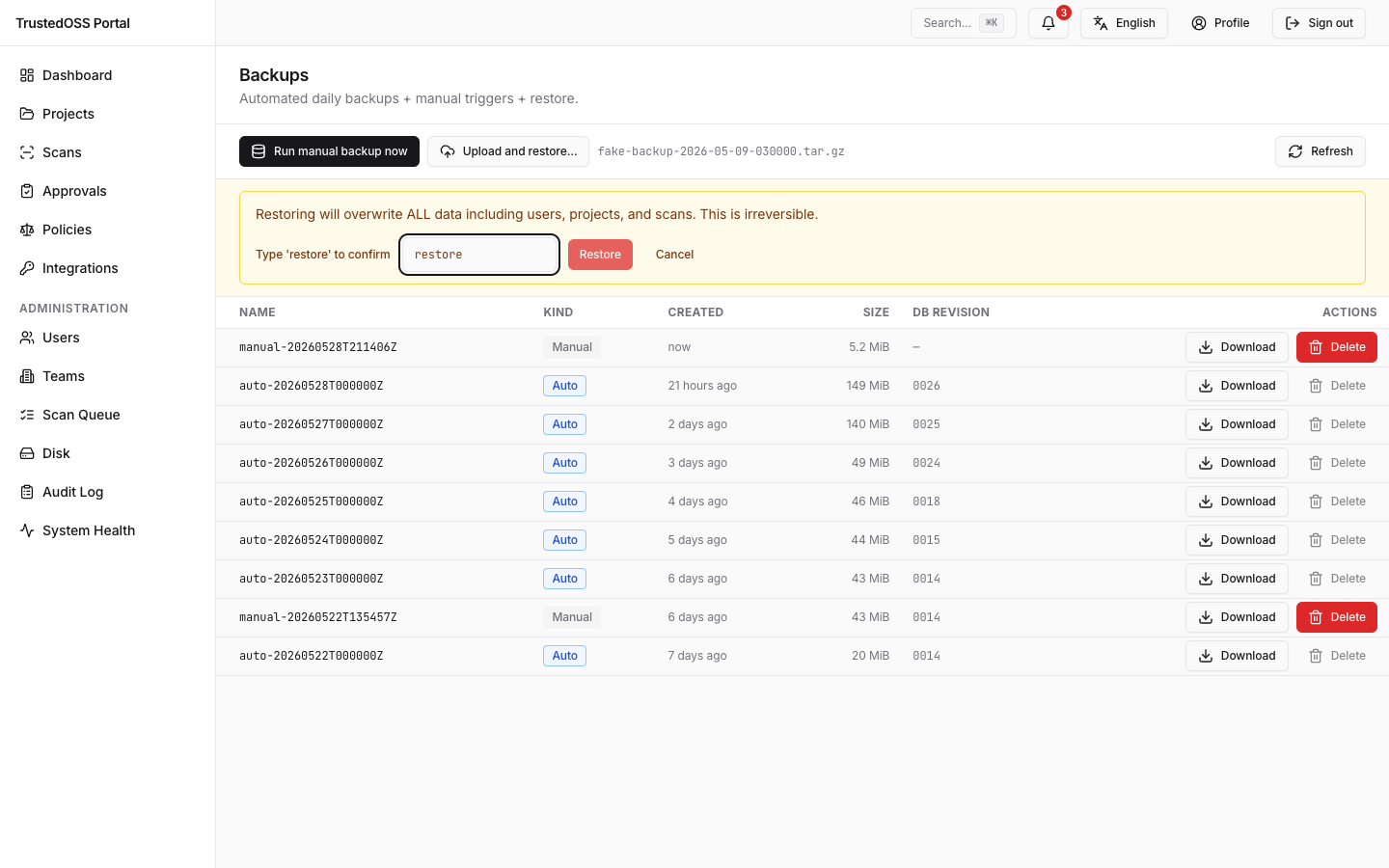
프론트엔드는 입력된 확인과 함께 명시적으로 X-Confirm-Restore: yes 헤더를 폼에 실어 제출하며, 백엔드는 복원 태스크를 큐에 넣기 전에 헤더와 super_admin 역할 모두를 검증합니다. 누락 또는 불일치 헤더는 HTTP 412 (Precondition Failed) 와 type=urn:trustedoss:problem:restore_confirmation_required, title="Restore confirmation header missing" 를 가진 problem document 로 응답합니다. 412 는 RFC 9110 §15.5.13 에 부합 — 요청 자체는 well-formed 이며 누락된 것은 파괴적 복원의 사전조건(precondition)입니다. 이중 게이트는 의도된 설계입니다 — 복원은 파괴적이고 되돌릴 수 없습니다.
진행은 수동 백업과 같은 방식으로 스트리밍됩니다. 복원이 완료되면 행이 succeeded로 전환되며 라이브 애플리케이션이 즉시 복원된 상태를 반영합니다(사용자 테이블 자체가 교체되므로 기존 JWT는 무효화됩니다).
자동 백업 스케줄링
cron이 가장 단순한 경��로입니다.
sudo crontab -e
# Minute Hour DoM Month DoW Command
0 3 * * * cd /opt/trustedoss-portal && bash scripts/backup.sh >> /var/log/trustedoss-backup.log 2>&1
호스트 로컬 시간 03:00에 매일 실행됩니다. 스택의 한가한 시간대로 시간을 조정하세요.
관리형 스케줄러(systemd 타이머)는 아래 systemd 타이머 레시피를 보세요.
호스트 외부 저장
로컬 백업은 데이터베이스 손상을 보호하지만 호스트 손실은 보호하지 않습니다. 보존 정책의 일부로 백업을 호스트 외부로 이동하세요.
# 예: AWS S3 야간 동기화(backup.sh 실행 후)
aws s3 sync /opt/trustedoss-portal/backups/ \
s3://acme-trustedoss-backups/ \
--exclude "*" --include "*.sql.gz" --include "*.tar.gz" --include "manifest.json" \
--storage-class STANDARD_IA
다른 대상도 동일: rclone copy(Backblaze B2, Wasabi, GCS), rsync(NFS / SSH), 기존 백업 에이전트.
백업에서 복원
bash scripts/restore.sh backups/2026-05-09-030000
확인 프롬프트:
About to restore from backups/2026-05-09-030000
! This will:
! - REPLACE the current database content
! - REPLACE /opt/trustedoss/workspace (if workspace.tar.gz present)
Continue? [y/N]
y 입력으로 진행.
스크립트 동작:
backend,frontend,worker,beat중지. Postgres + Redis 유지.postgres.sql.gz를 라이브 데이터베이스로 복원(pg_dump --clean이 객체 drop 선행).workspace.tar.gz를WORKSPACE_HOST_PATH로 복원(기존 파일은 먼저 제거).- 애플리케이션 컨테이너 재시작.
- 라이브 Alembic head가
manifest.json과 일치하는지 검증, 불일치 시 경고.
성공 시 출력:
✓ database restored
✓ workspace restored
✓ application restarted
✓ alembic head matches manifest (9f1c8d2a3b4e)
Restore complete
재해 복구 런북
호스트 전체가 손실되면:
-
동일 OS·커널·Docker 버전의 대체 호스트 프로비저닝.
-
bash scripts/install.sh로 포털 설치. 가능하면 동일 공개 URL 사용(DNS 재포인팅). -
상태를 깔끔히 교체하기 위해 스택 중지:
docker-compose -f docker-compose.yml stop backend frontend worker beat -
호스트 외부 저장소에서 백업 복사:
aws s3 cp s3://acme-trustedoss-backups/backups/2026-05-09-030000 \/opt/trustedoss-portal/backups/2026-05-09-030000 --recursive -
복원:
bash scripts/restore.sh backups/2026-05-09-030000 -
원래 super-admin으로 로그인. 프로젝트·스캔·감사 로그 검증.
S3에 백업이 있는 작은 설치라면 전체 DR(호스트 손실 → 복원된 포털)이 30분 내에 진행됩니다.
Forward-only 마이그레이션과 복원
포털은 alembic downgrade를 지원하지 않습니다. 이전 백업이 직접 소비할 수 없는 상태로 마이그레이션이 스키마를 둔 새 릴리스로 업그레이드한 경우, 복원 스크립트의 manifest 체크가 경고합니다.
! alembic head mismatch. expected=9f1c8d2a3b4e current=ab12cd34ef56
! Run: docker-compose -f docker-compose.yml exec backend alembic upgrade head
해결: 복원된 데이터베이스는 이전 head이고 현재 컨테이너 코드는 새 head입니다. 두 옵션:
- 코드를 롤백 —
.env의IMAGE_TAG를 백업을 만든 버전으로 변경 후docker-compose -f docker-compose.yml up -d. 스키마와 코드가 일치합니다. - Forward 마이그레이션 재적용 — 복원된 데이터베이스에서
alembic upgrade head. Forward-only 데이터 마이그레이션은 멱등이라 깔끔히 재실행되어야 합니다. 스테이징에서 먼저 테스트하세요.
사고 복구 시 옵션 (1) 권장, 의도된 계획 단계에서만 옵션 (2) 권장.
암호화된 백업
덤프는 평문 SQL입니다. 저장 시 암호화:
bash scripts/backup.sh
gpg --symmetric --cipher-algo AES256 \
backups/2026-05-09-030000/postgres.sql.gz
gpg --symmetric --cipher-algo AES256 \
backups/2026-05-09-030000/workspace.tar.gz
shred -u backups/2026-05-09-030000/{postgres.sql.gz,workspace.tar.gz}
복원 시 gpg --decrypt를 먼저, 그 다음 표준 복원 흐름. 분기별로 복호화 경로를 테스트하세요.
systemd 타이머 레시피
cron 대신 systemd 타이머를 선호한다면:
# /etc/systemd/system/trustedoss-backup.service
[Unit]
Description=TRUSCA nightly backup
[Service]
Type=oneshot
WorkingDirectory=/opt/trustedoss-portal
ExecStart=/usr/bin/env bash scripts/backup.sh
StandardOutput=journal
StandardError=journal
# /etc/systemd/system/trustedoss-backup.timer
[Unit]
Description=TRUSCA nightly backup timer
[Timer]
OnCalendar=*-*-* 03:00:00
Persistent=true
[Install]
WantedBy=timers.target
활성화:
sudo systemctl daemon-reload
sudo systemctl enable --now trustedoss-backup.timer
정상 동작 확인
백업 후:
backups/아래 새 디렉터리에 예상한 세 파일이 존재.
manifest.json이 JSON으로 디코드되며 비어 있지 않은alembic_head를 포함.
gunzip -t backups/.../postgres.sql.gz성공(gzip 무결성 체크).
복원 후:
- 백업 시점의 자격증명으로 포털에 깔끔히 로그인.
- 프로젝트 수·스캔 수·감사 로그 행 수가 예상과 일치.
- /admin/health가 모두 녹색.
트러블슈팅
docker-compose logs --tail=500 beat | grep daily-auto-backup— beat 스케줄러가 예정대로 태스크를 발사했는가?docker-compose logs --tail=2000 worker | grep "backup\."— 태스크 결과(completed / failed / pruned / restored)./admin/backup/listAPI — 가장 최근 시도 + 상태.
pg_dump가 권한 거부 오류
스크립트는 postgres 컨테이너 안에서 pg_dump를 실행합니다 — 호스트 권한 문제는 없어야 합니다. .env의 POSTGRES_USER가 라이브 사용자와 일치하는지 확인:
docker-compose -f docker-compose.yml exec postgres \
psql -U postgres -c '\du'
Workspace 단계에서 복원 중단
스크립트는 tar 추출 전에 rm -rf "$WORKSPACE_HOST_PATH"를 실행합니다. 디렉터리가 read-only 마운트이거나 다른 프로세스가 사용 중이면 rm이 실패합니다. 마운트를 풀고 재실행하세요.
"alembic head mismatch" 경고
백업 스크립트가 빈 workspace tar로 조용히 성공
tar는 archive 동안 변경되는 파일을 건너뜁니다. workspace가 활발히 변하면 백업 전 워커를 중지하세요.
docker-compose -f docker-compose.yml stop worker
bash scripts/backup.sh
docker-compose -f docker-compose.yml start worker
이는 30초 스캔-일시 정지 윈도와 일관성 보장된 workspace tar를 교환합니다.
로드맵
다음 기능들은 초기 문서에 언급되었으나 v0.10.0 에는 반영되지 않았습니다.
BACKUP_DAILY_ENABLED=falseenv 토글로 Celery Beat 일일 스케줄을 옵트아웃(현재는 스케줄이 항상 켜져 있음 — 호스트 스케줄러를 추가로 사용하되 대체로는 사용하지 마세요).