디스크 및 시스템 health
포털은 두 운영자 대시보드를 /admin 아래 노출합니다.
- /admin/health — 모든 컨테이너 서비스와 Trivy DB 신선도 카드(roadmap)의 현재 상태.
- /admin/disk — workspace와 데이터베이스 저장소 사용량(설정 가능한 hard limit 포함).
이 둘이 함께 사용자가 알아채기 전에 문제를 잡습니다.
호스트를 운영하는 super_admin. docker-compose ps와 기본 셸에 익숙해야 합니다.
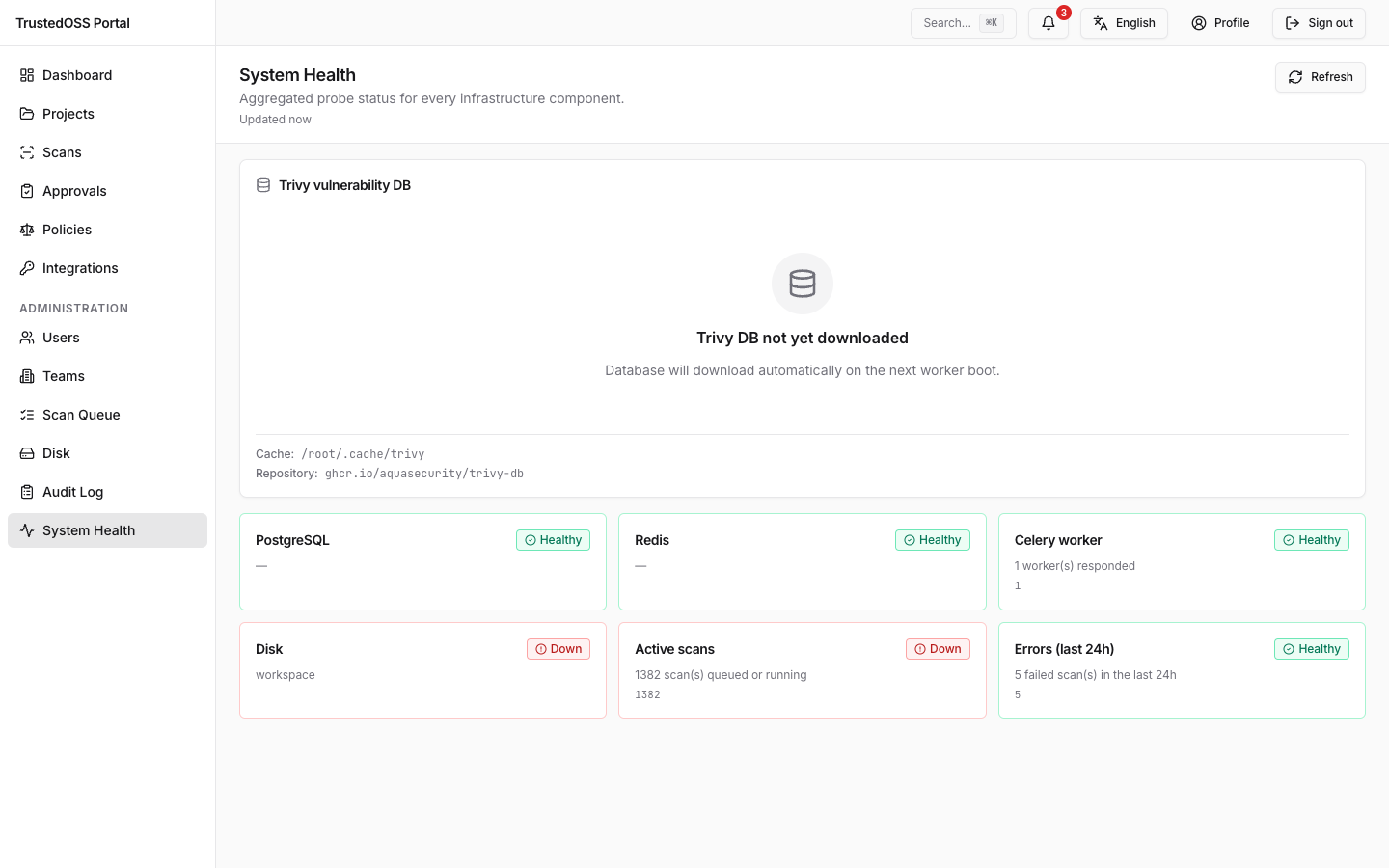
시스템 health 대시보드
/admin/health 페이지는 포털이 의존하는 모든 컴포넌트를 나열합니다. 각 행:
- 컴포넌트 —
postgres,redis,celery,disk,active_scans,last_24h_errors중 하나. Trivy DB 신선도는 같은 페이지의 별도 패널에 표시됩니다(취약점 데이터 참고). - 상태 —
ok(녹색),degraded(노랑),down(빨강). UI 라벨은 로케일에 따라 다르나(EN 로케일은 "OK / Degraded / Down" 표시) API 계약은 위 소문자 enum을 발신합니다. - 상세 —
ok가 아닐 때의 오류 메시지 또는 텔레메트리 요약.
모든 프로브는 페이지(또는 API)가 요청하는 시점에 동기로 실행됩니다. 따라서 행마다 "마지막 점검" 시각이 따로 있는 것이 아니라 페이지 헤더에 마지막 갱신 타임스탬프 하나가 표시되며, 페이지의 모든 카드는 같은 프로브 실행 결과를 반영합니다.
대시보드는 React Query 폴링으로 자동 갱신됩니다(기본 30초; 사용자는 페이지 헤더에서 폴링을 일시 정지 가능). WebSocket 스트림이 아닙니다 — 벽 디스플레이를 원하는 운영자는 탭을 열어 두면 폴링 갱신에 의존할 수 있습니다.
Health 프로브
각 행은 services/admin_health_service.py의 실제 프로브에 매핑됩니다.
| 컴포넌트 | 프로브 |
|---|---|
postgres | 애플리케이션의 asyncpg 풀로 SELECT 1. |
redis | asyncio 클라이언트를 통한 redis-cli ping 동등 호출. |
celery | Celery inspect ping이 설정 타임아웃 이내 응답. |
disk | Workspace 볼륨 사용량을 warn / critical 임계와 비교. |
active_scans | 현재 running 상태인 스캔 수 — 정보성, 큐 길이가 내부 임계를 넘으면 degraded 노출. |
last_24h_errors | 최근 24시간 동안 ERROR 레벨 구조화 로그 이벤트 수 — 정보성. |
포털은 backend, worker, beat, frontend, traefik을 별도 프로브하지 않습니다. 이들의 liveness 는 암묵적입니다 — 대시보드가 렌더되면 backend 가동 중, celery 행이 ok이면 worker(와 worker 가 의존하는 broker)도 도달 가능.
endoflife.date 스냅숏 패널
Trivy DB·KEV 피드 패널 아래의 endoflife.date 스냅숏 패널은 Components 탭 EOL 배지의 데이터셋 상태를 보여줍니다.
- 스냅숏 날짜 — 유효 데이터셋의 생성일(릴리즈에 벤더링된 스냅숏과,
EOL_REFRESH_ENABLED=true인 경우 마지막으로 수집한 스냅숏 중 더 최신). 180일이 지나면 주황색 오래됨 배지로 격상됩니다 — 릴리즈를 업그레이드하거나python3 scripts/refresh_eol_snapshot.py로 스냅숏을 다시 만드십시오. - 지원 종료 컴포넌트 — 지원 종료를 지난 카탈로그 컴포넌트 버전의 실시간 개수.
- 최근 기록 / 해제 — 주간 beat 의 재기록 패스가 마지막 실행에서 한 일. 재기록은 실시간 수집이 꺼져 있어도 실행됩니다 — 순수 로컬 패스로, 더 새 벤더 스냅숏을 기존 행에 반영하고 목록에서 빠진 제품의 기록을 지웁니다.
- 다음 실행 — 라이브 Celery beat 스케줄에서 유도(기본 일요일 02:15 UTC).
푸터에는 데이터셋 출처(벤더링/피드 수집)와 실시간 갱신 여부가 표시됩니다.
실시간 갱신은 기본 꺼짐입니다 — 환경변수의
EOL_REFRESH_ENABLED 를 참고하십시오.
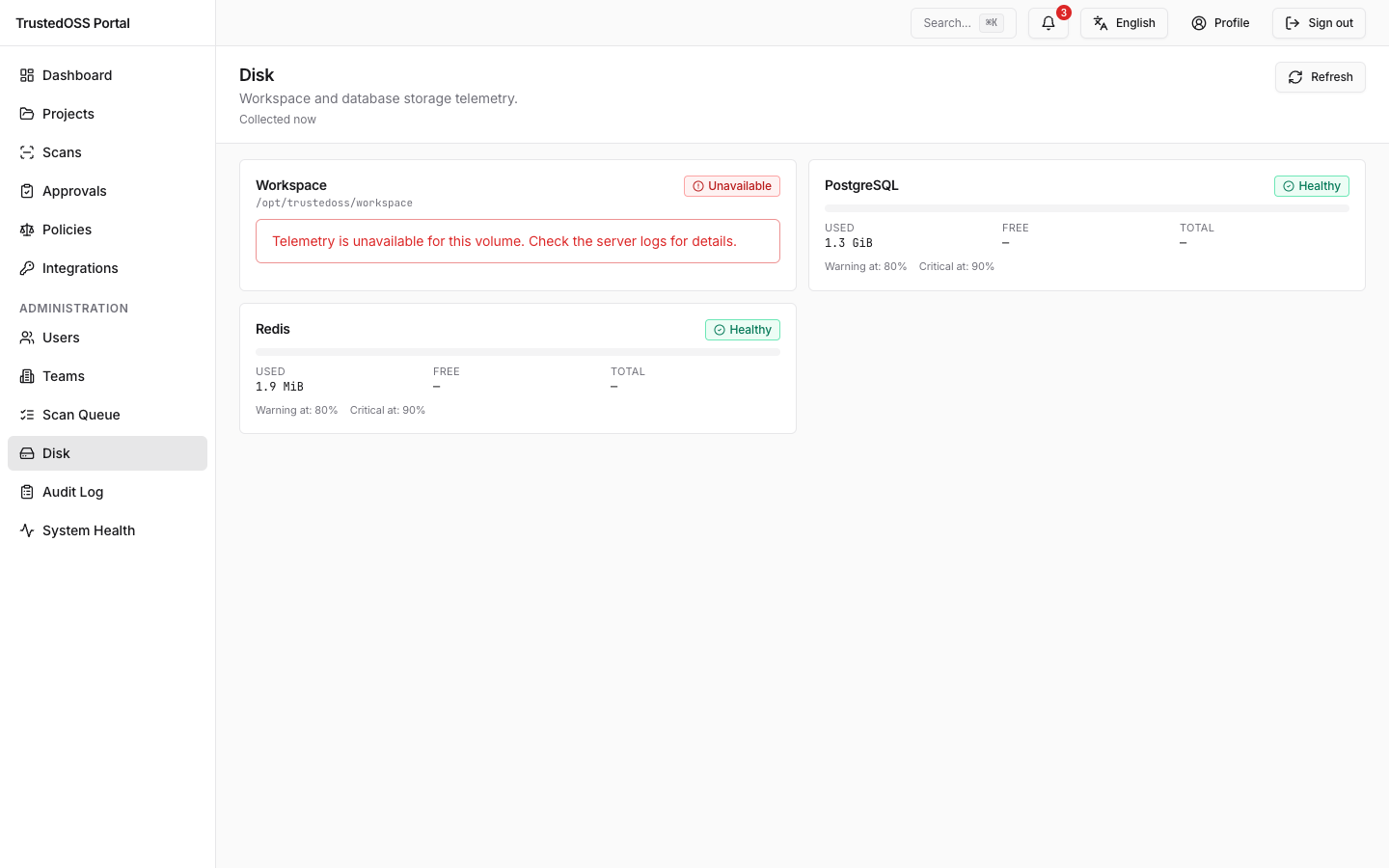
디스크 대시보드
/admin/disk는 포털이 신경 쓰는 파일시스템마다 카드 하나를 렌더합니다. 현재 릴리스의 실제 카드는 workspace, trivy_db, postgres, redis 입니다(API 가 items: AdminDiskItem[] 으로 반환하고 페이지가 항목당 카드 하나를 렌더). 이전 dt_volume 카드는 Dependency-Track 폐기와 함께 제거되었습니다.
각 카드는 warn 임계와 critical 임계가 있습니다.
| 임계 | 기본 | 효과 |
|---|---|---|
| Warn | 80% | 노란 카드, 대시보드 배너, 다른 부수 효과 없음. |
| Critical | 90% | 빨간 카드, 대시보드 배너, admin 알림 발신. |
.env에서 변경:
DISK_THRESHOLD_WARNING_PCT=80
DISK_THRESHOLD_CRITICAL_PCT=90
별개로 스캔 disk-guard는 단일 DISK_HARD_LIMIT_PCT(기본 95)를 사용해 workspace 볼륨이 그 라인을 넘으면 신규 스캔을 차단합니다. 분리는 의도된 설계입니다 — 대시보드는 더 이르게(80% / 90%) 경고하고 스캔 가드는 더 늦게(95%) 동작해 운영자에게 놀람을 주지 않으면서 출혈을 막습니다.
DISK_HARD_LIMIT_PCT=95
"스캔 차단"의 의미
DISK_HARD_LIMIT_PCT가 트립되면 POST /v1/projects/{id}/scans가 다음을 반환합니다.
{
"type": "about:blank",
"title": "Workspace Disk Full",
"status": 503,
"detail": "Workspace is at 96% (hard limit 95%). Free space and try again.",
"instance": "/v1/projects/01H…/scans"
}
진행 중 스캔은 종료되지 않습니다; 새 제출만 거부됩니다. 작업 손실을 피하면서 출혈은 막습니다.
디스크가 가득 찼을 때 할 일
1. 원인 식별
스캔 workspace는 WORKSPACE_HOST_PATH에 있습니다. 프로덕션 compose(docker-compose.yml)는 컨테이너 안에서 이 값을 /workspace로 설정합니다. .env에서 재정의했다면 그 경로로 바꾸십시오. 각 스캔은 ${WORKSPACE_HOST_PATH}/<scan_id>/ 디렉터리를 생성합니다.
docker-compose -f docker-compose.yml exec backend \
du -sh "${WORKSPACE_HOST_PATH:-/workspace}"/* | sort -h | tail -20
대개 단일 스캔의 소스 클론(<scan_id>/source/) + scancode 라이선스 탐지 출력(<scan_id>/scancode/scancode.json)이 workspace를 지배합니다. cdxgen 캐시(<scan_id>/cdxgen/)도 시간이 지나면서 커집니다.
2. 공간 확보
# 30일 이상 지난 scancode 결과 JSON 삭제(안전 — 다음 스캔에서 재생성).
docker-compose -f docker-compose.yml exec backend \
find "${WORKSPACE_HOST_PATH:-/workspace}" -name "scancode.json" -mtime +30 -delete
# 30일 이상 지난 cdxgen SBOM 캐시 삭제(안전 — 다음 스캔에서 재생성).
docker-compose -f docker-compose.yml exec backend \
find "${WORKSPACE_HOST_PATH:-/workspace}" -type d -name "cdxgen" -mtime +30 -exec rm -rf {} +
# 완료된 스캔 하나의 workspace 디렉터리 통째 삭제.
docker-compose -f docker-compose.yml exec backend \
rm -rf "${WORKSPACE_HOST_PATH:-/workspace}/<scan-id>/"
3. 검증
정리 후 /admin/disk가 ~10초 이내에 갱신됩니다. Hard 임계 아래로 내려가면 스캔이 자동으로 다시 수락됩니다 — 서비스 재시작 불필요.
4. 장기 대응
WORKSPACE_HOST_PATH를 더 큰 볼륨으로 이동(.env편집,backend·worker재시작).- 로컬 백업이 공간을 잡아먹으면
BACKUP_RETENTION_DAYS축소. - 백업을 호스트 외부(S3, NFS)로 이동하고 로컬 정리 생략.
알림 트리거
디스크 압박은 현재 알림을 생성하지 않습니다 — 운영자는 /admin/disk를 직접 모니터링해야 합니다. disk_pressure 알림 종류는 로드맵 항목입니다.
/admin/scans — 스캔 큐와 워커 모니터링
/admin/scans 페이지(super-admin 전용)는 조직 전체의 실행 중·대기·성공·실패 스캔을 나열합니다. 운영자는 다음을 수행할 수 있습니다.
- 임의 태스크의 전체 progress 페이로드 + 마지막 로그 프레임 검사.
- 멈춘 스캔 강제 취소(
POST /v1/admin/scans/{scan_id}/cancel). - 상태·종류·프로젝트 이름으로 필터링. (워커별 필터는 없습니다 — 스캔은 어느 워커가 집어 갔는지 기록하지 않습니다.)
백엔드: apps/backend/api/v1/admin/scans.py. UI: apps/frontend/src/features/admin/scans/AdminScansPage.tsx.
정상 동작 확인
변경 후:
- /admin/health가 모두 녹색.
- /admin/disk가 warn 라인 아래.
- 임의 프로젝트 대상 테스트 스캔이 end-to-end 성공.
트러블슈팅
docker-compose logs --tail=200 backend | grep disk_threshold— 임계 검사 태스크의 직전 판정./admin/diskAPI — 카드별 분해 JSON(workspace, trivy_db, postgres, redis).- 호스트:
df -h /opt/trustedoss && docker system df.
Health 페이지는 모두 healthy인데 사용자가 불만
대시보드는 liveness 스냅샷이지 전체 기능 보장이 아닙니다. Liveness가 통과하더라도 다음이 가능:
- 워커가 작업을 받았으나 하위 프로세스에서 멈춤(매우 드뭄). 워커 재시작.
- Trivy DB가 디스크에 있지만 오래 갱신되지 않음 — 주간 refresh 확인은 취약점 데이터 — 트러블슈팅 참조.
디스크 게이지가 잘못됨
게이지는 backend 컨테이너 내부에서 호스트 마운트 볼륨을 읽습니다. 최근에 WORKSPACE_HOST_PATH를 변경하고 재시작을 잊으면 게이지가 이전 볼륨을 가리킵니다. backend 재시작.
Hard limit가 너무 공격적
높이세요. 95%는 호스트 디스크가 바닥나기 전에 운영자가 대응할 여유를 주는 DISK_HARD_LIMIT_PCT의 보수적 기본값입니다. 모니터링이 더 이르게 잡으면 낮출 수 있습니다. Warn 임계(80%) 이상에서 일상 운영하는 것은 디스크 추가 신호입니다.
로드맵
다음 기능들은 초기 문서에 언급되었으나 v0.10.0 에는 반영되지 않았습니다.
- Health 대시보드의
backend,worker,beat,frontend,traefik컴포넌트별 liveness 프로브(현재는 대시보드 렌더링과celery행에서 추론). - WebSocket 스트리밍 health 갱신(현재는 React Query 폴링 사용).
- 계획된
vulnerability_data행 이외 컴포넌트의 다중 샷 연속-미스 상태 머신.