Backup & restore
The portal ships two scripts: scripts/backup.sh and scripts/restore.sh. They cover the two artifacts that contain state — the PostgreSQL database and the workspace volume — plus a manifest that records the Alembic head at backup time.
super_admin with sudo on the host. Familiarity with pg_dump, tar, and cron.
What is in a backup
Two directory naming formats coexist in this release:
- CLI legacy —
backups/YYYY-MM-DD-HHMMSS/(used byscripts/backup.shand the examples below). - UI / Celery —
backups/(auto|manual)-YYYYMMDDTHHMMSSZ/(used byapps/backend/tasks/backup.pyand the/admin/backuppage; the prefix marks whether the backup came from the daily Celery Beat job or an operator click). Theauto-retention sweep that the Trigger a backup section refers to keys off this prefix.
Both formats decode to the same postgres.sql.gz + workspace.tar.gz + manifest.json triple and are interchangeable on the restore side; the restore script (and the UI restore endpoint) accept either.
backups/2026-05-09-030000/
├── postgres.sql.gz # pg_dump --clean --if-exists | gzip
├── workspace.tar.gz # tar -czf of $WORKSPACE_HOST_PATH
└── manifest.json # timestamp, alembic head, db size, workspace path
postgres.sql.gz— full logical dump with--clean --if-exists. Re-applying it drops + recreates objects, then re-inserts data.workspace.tar.gz— the host directory mounted into the worker as/workspace. Contains the per-scan source clones (<scan_id>/source/), the scancode license-detection output (<scan_id>/scancode/scancode.json), and the cdxgen SBOM cache (<scan_id>/cdxgen/).manifest.json—timestamp,alembic_head,db_size,workspace_path. The restore script validatesalembic_headagainst the live state.
The portal does not back up .env (it contains secrets — store it via your existing secret-management tooling) and does not back up Traefik's ACME state (Let's Encrypt re-issues certificates within minutes).
Take a manual backup
bash scripts/backup.sh
Output:
Backup → backups/2026-05-09-030000
✓ wrote backups/2026-05-09-030000/postgres.sql.gz (12M)
✓ wrote backups/2026-05-09-030000/workspace.tar.gz (840M)
✓ wrote backups/2026-05-09-030000/manifest.json (alembic head = 9f1c8d2a3b4e)
Backup complete
backups/2026-05-09-030000
The script prunes backups older than BACKUP_RETENTION_DAYS (default 7) at the end. Pass --no-prune to skip pruning.
Manual backup with the admin UI
For operators who prefer the browser, /admin/backup exposes the same backup and restore flows without dropping to a shell.
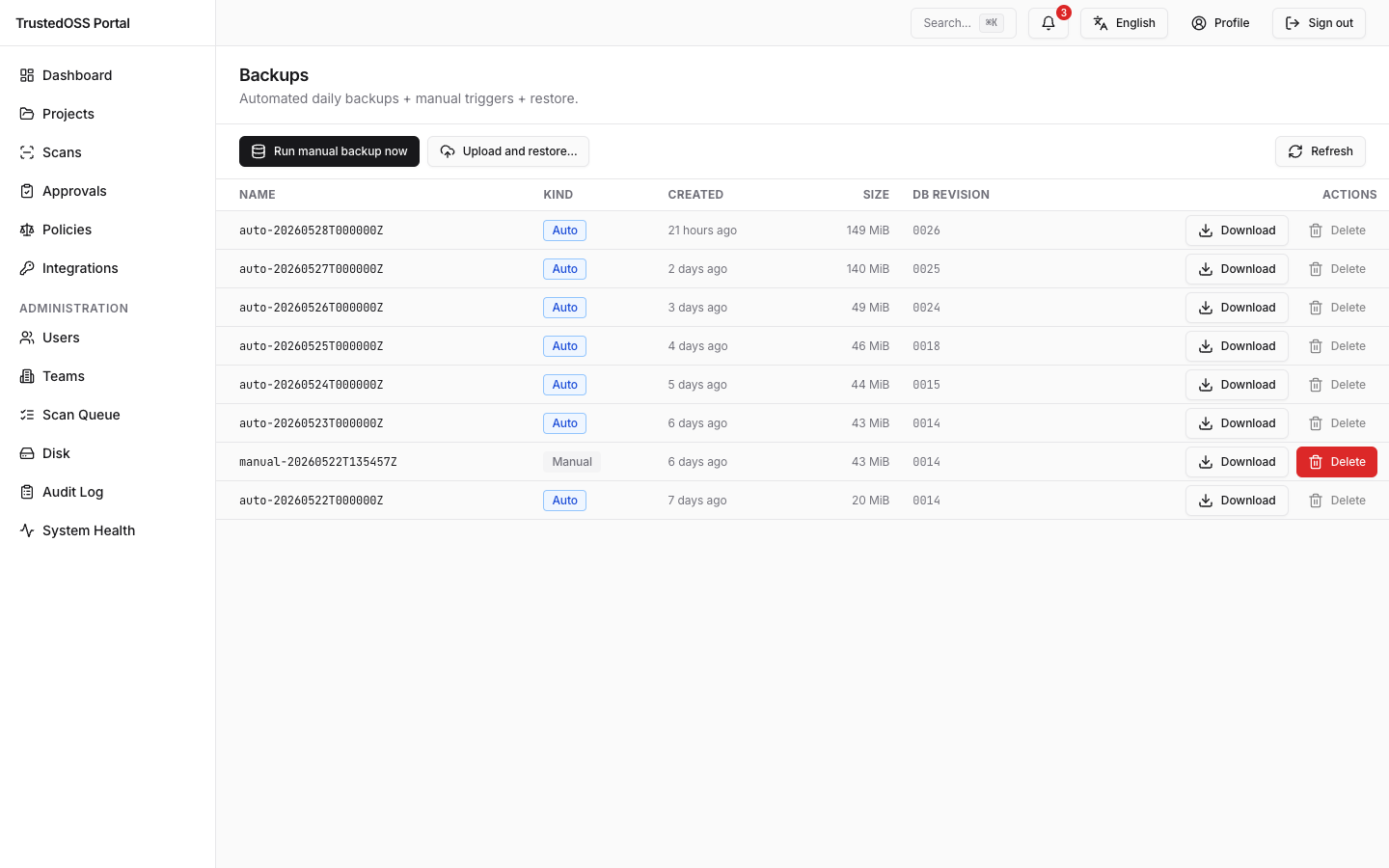
The list renders six columns: NAME, KIND, CREATED, SIZE, DB REVISION, ACTIONS. On a fresh install the body shows the inline empty card ("No backups yet…") — populate it via the toolbar (Run manual backup now or Upload and restore…) or wait for the nightly auto job.
Trigger a backup
- Open
/admin/backup(Admin sidebar → Backup). - Click Run manual backup now. The button is
super_admin-only. - The portal queues a Celery task; the row appears in the table immediately with status
runningand a live-updating progress bar. - When the task completes, the row flips to
succeededand a Download link becomes available next to the timestamp.
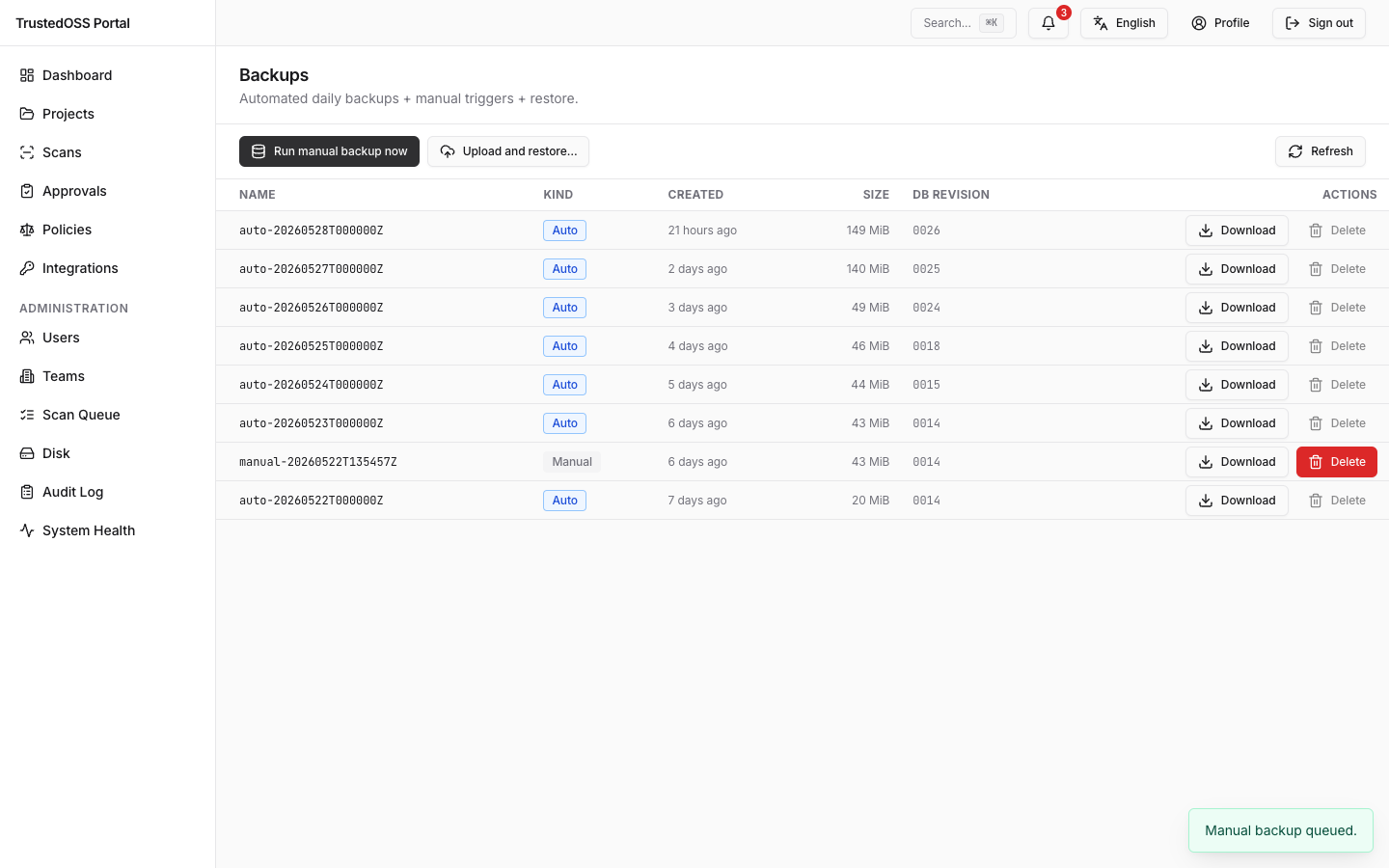
The list table shows: timestamp, size, auto badge (set on backups created by Celery Beat), Download, and Delete. Auto-tagged backups display a lock icon — they are subject to the 7-day automatic retention policy and are pruned in chronological order. Manual backups have no automatic retention and are deleted only when you click Delete.
Schedule via Celery Beat
Daily backups at 00:00 UTC are scheduled by default in apps/backend/tasks/backup.py and require no additional configuration. The schedule is always-on in this release — there is no env toggle to disable it (a BACKUP_DAILY_ENABLED switch is on the roadmap). If you prefer a host-side scheduler instead of Celery Beat, treat the auto-backups as a safety net and add the cron / systemd recipes below; the workflows are independent.
Upload + restore from the UI
The Upload + Restore section accepts a previously downloaded .tar.gz archive (the bundle that scripts/backup.sh produces).
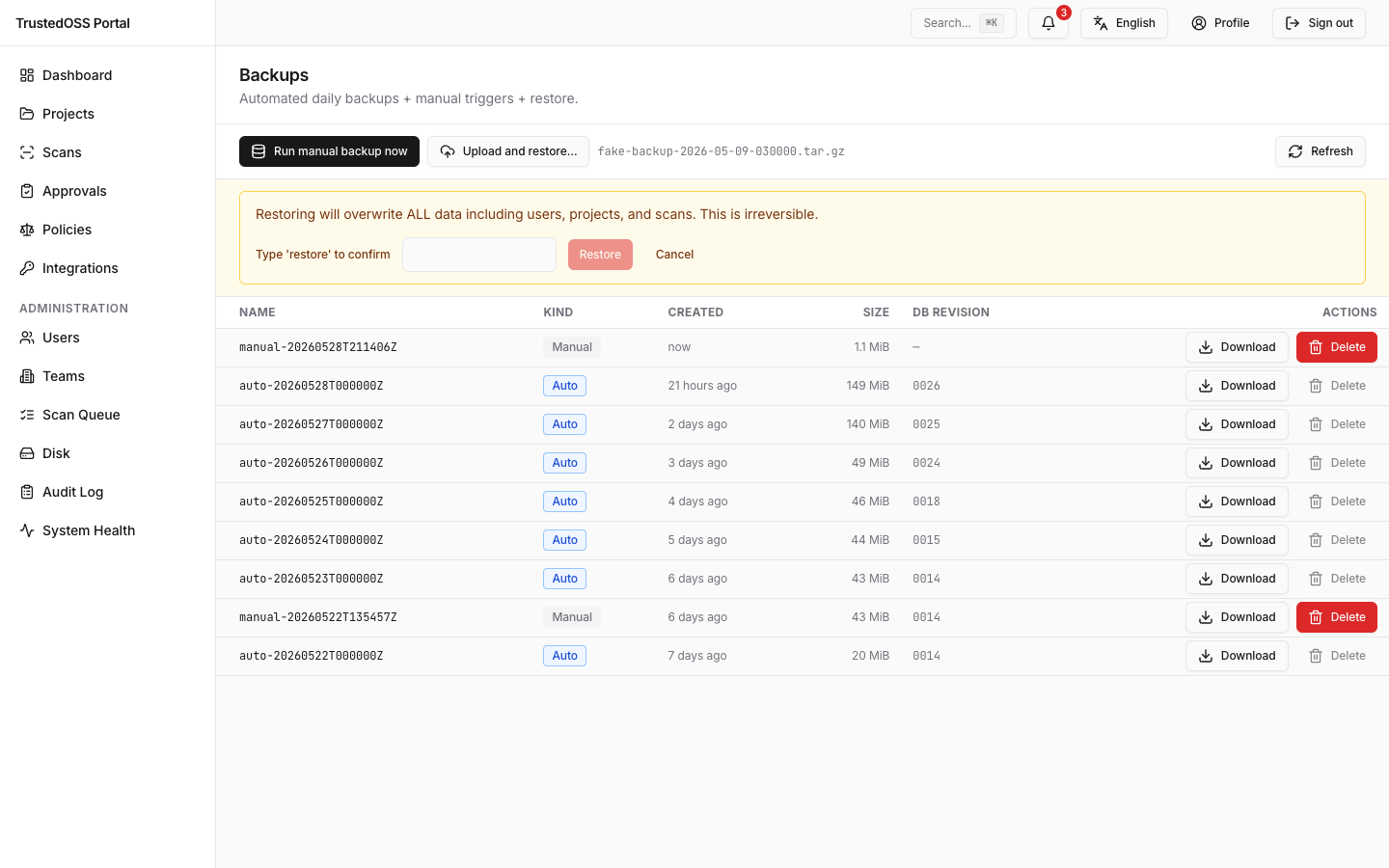
- Click Choose file and select the archive (max 10 GB — larger backups must use the CLI restore path).
- Read the warning panel carefully. The restore overwrites the live database and workspace.
- Type the word
restore(lower case, exact match) into the confirmation field. The Restore button stays disabled until the typing-gate matches. - Click Restore.
Once the typing-gate matches, the destructive Restore button enables. The screenshot below captures the moment the gate unlocks — the typed restore token, the visible warning panel, and the now-actionable button:
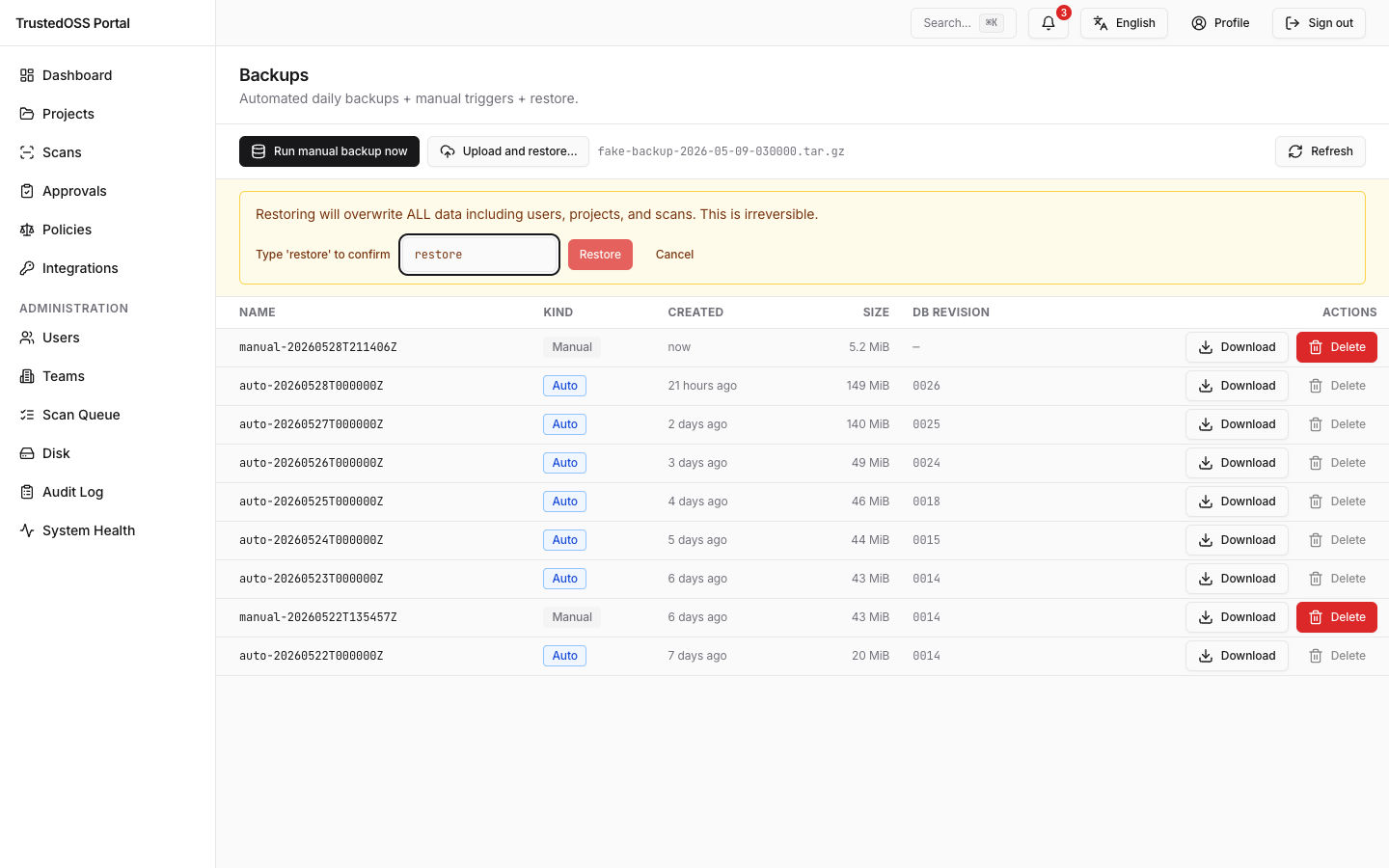
The frontend submits the form with an explicit X-Confirm-Restore: yes header alongside the typed confirmation; the backend validates both the header and the super_admin role before queuing the restore task. Missing or mismatched headers return HTTP 412 (Precondition Failed) with a problem document carrying type=urn:trustedoss:problem:restore_confirmation_required and title="Restore confirmation header missing". The 412 status matches RFC 9110 §15.5.13 — the request shape is well-formed; what is missing is the destructive-restore precondition. The double-gate is deliberate — restore is destructive and irreversible.
Progress streams the same way as a manual backup. A completed restore flips the row to succeeded and the live application reflects the restored state immediately (existing JWTs are revoked because the user table itself is replaced).
Schedule automated backups
cron is the simplest path:
sudo crontab -e
# Minute Hour DoM Month DoW Command
0 3 * * * cd /opt/trustedoss-portal && bash scripts/backup.sh >> /var/log/trustedoss-backup.log 2>&1
This runs at 03:00 host-local time daily. Adjust the hour to a quiet window for your stack.
For a managed scheduler (systemd timer), see the systemd recipe below.
Off-host storage
Local backups protect against database corruption but not against host loss. Move backups off-host as part of your retention policy:
# Example: AWS S3 nightly sync (run after backup.sh)
aws s3 sync /opt/trustedoss-portal/backups/ \
s3://acme-trustedoss-backups/ \
--exclude "*" --include "*.sql.gz" --include "*.tar.gz" --include "manifest.json" \
--storage-class STANDARD_IA
Other targets work the same way: rclone copy (Backblaze B2, Wasabi, GCS), rsync (NFS / SSH), or your existing backup agent.
Restore from a backup
bash scripts/restore.sh backups/2026-05-09-030000
You will be prompted to confirm:
About to restore from backups/2026-05-09-030000
! This will:
! - REPLACE the current database content
! - REPLACE /opt/trustedoss/workspace (if workspace.tar.gz present)
Continue? [y/N]
Type y to proceed.
The script:
- Stops
backend,frontend,worker,beat. Postgres + Redis stay up. - Restores
postgres.sql.gzinto the live database (pg_dump --cleandrops objects first). - Restores
workspace.tar.gzintoWORKSPACE_HOST_PATH(existing files are removed first). - Restarts the application containers.
- Verifies the live Alembic head matches
manifest.jsonand warns if not.
A successful restore prints:
✓ database restored
✓ workspace restored
✓ application restarted
✓ alembic head matches manifest (9f1c8d2a3b4e)
Restore complete
Disaster-recovery runbook
If the host is lost entirely:
-
Provision a replacement host with the same OS / kernel / Docker version.
-
Install the portal with
bash scripts/install.sh. Use the same public URL where possible (your DNS will repoint). -
Stop the stack so you can swap state cleanly:
docker-compose -f docker-compose.yml stop backend frontend worker beat -
Copy a backup from off-host storage:
aws s3 cp s3://acme-trustedoss-backups/backups/2026-05-09-030000 \/opt/trustedoss-portal/backups/2026-05-09-030000 --recursive -
Restore:
bash scripts/restore.sh backups/2026-05-09-030000 -
Sign in as the original super-admin. Verify projects, scans, and audit log.
Full DR (host loss → restored portal) runs in 30 minutes for a small install with backups in S3.
Forward-only migrations and restore
The portal does not support alembic downgrade. If you upgrade to a release whose migration leaves the schema in a state your older backup cannot consume directly, the restore script's manifest check will warn:
! alembic head mismatch. expected=9f1c8d2a3b4e current=ab12cd34ef56
! Run: docker-compose -f docker-compose.yml exec backend alembic upgrade head
Resolution: the restored database is at the older head. The current container code is at the newer head. Two options:
- Roll the code back —
IMAGE_TAGin.envto the version that produced the backup, thendocker-compose -f docker-compose.yml up -d. The schema and code now match. - Re-apply forward migrations —
alembic upgrade headon the restored database. Forward-only data migrations should re-run cleanly because they are idempotent. Test this in a staging environment first.
We recommend option (1) for incident recovery and option (2) only as a deliberate planned step.
Encrypted backups
The dump is plaintext SQL. To encrypt at rest:
bash scripts/backup.sh
gpg --symmetric --cipher-algo AES256 \
backups/2026-05-09-030000/postgres.sql.gz
gpg --symmetric --cipher-algo AES256 \
backups/2026-05-09-030000/workspace.tar.gz
shred -u backups/2026-05-09-030000/{postgres.sql.gz,workspace.tar.gz}
Restoring requires gpg --decrypt first, then the standard restore flow. Test the decrypt path quarterly.
systemd timer recipe
If you prefer systemd timers over cron:
# /etc/systemd/system/trustedoss-backup.service
[Unit]
Description=TRUSCA nightly backup
[Service]
Type=oneshot
WorkingDirectory=/opt/trustedoss-portal
ExecStart=/usr/bin/env bash scripts/backup.sh
StandardOutput=journal
StandardError=journal
# /etc/systemd/system/trustedoss-backup.timer
[Unit]
Description=TRUSCA nightly backup timer
[Timer]
OnCalendar=*-*-* 03:00:00
Persistent=true
[Install]
WantedBy=timers.target
Enable:
sudo systemctl daemon-reload
sudo systemctl enable --now trustedoss-backup.timer
Verify it worked
After running a backup:
- The new directory under
backups/exists with the three expected files.
manifest.jsondecodes as JSON and has a non-emptyalembic_head.
gunzip -t backups/.../postgres.sql.gzsucceeds (gzip integrity check).
After running a restore:
- The portal signs in cleanly with the credentials from the backup era.
- Project counts, scan counts, and audit-log row counts match expectations.
- /admin/health is all green.
Troubleshooting
docker-compose logs --tail=500 beat | grep daily-auto-backup— beat scheduler fired the task on schedule?docker-compose logs --tail=2000 worker | grep "backup\."— task outcome (completed / failed / pruned / restored)./admin/backup/listAPI — most recent attempt + status.
pg_dump errors with permission denied
The script runs pg_dump inside the postgres container — there should be no host permission issue. Confirm .env's POSTGRES_USER matches the live user:
docker-compose -f docker-compose.yml exec postgres \
psql -U postgres -c '\du'
Restore aborts at workspace step
The script runs rm -rf "$WORKSPACE_HOST_PATH" before extracting the tar. If the directory is on a read-only mount or is in use by another process, the rm fails. Free the mount and re-run.
"alembic head mismatch" warning
See forward-only migrations and restore.
Backup script silently succeeds with empty workspace tarball
tar skips files that change during the archive. Stop the worker before backup if your workspace churns aggressively:
docker-compose -f docker-compose.yml stop worker
bash scripts/backup.sh
docker-compose -f docker-compose.yml start worker
This trades a 30-second scan-pause window for a guaranteed-consistent workspace tar.
Roadmap
The following affordances are referenced in early docs but are not shipped in this release:
BACKUP_DAILY_ENABLED=falseenv toggle to opt out of the Celery Beat daily schedule (today the schedule is always-on; use the host scheduler in addition, not as a replacement).